Don’t let the blue screen of death kill your operations: Understanding & learning from the Windows/Crowdstrike outage
23 July 2024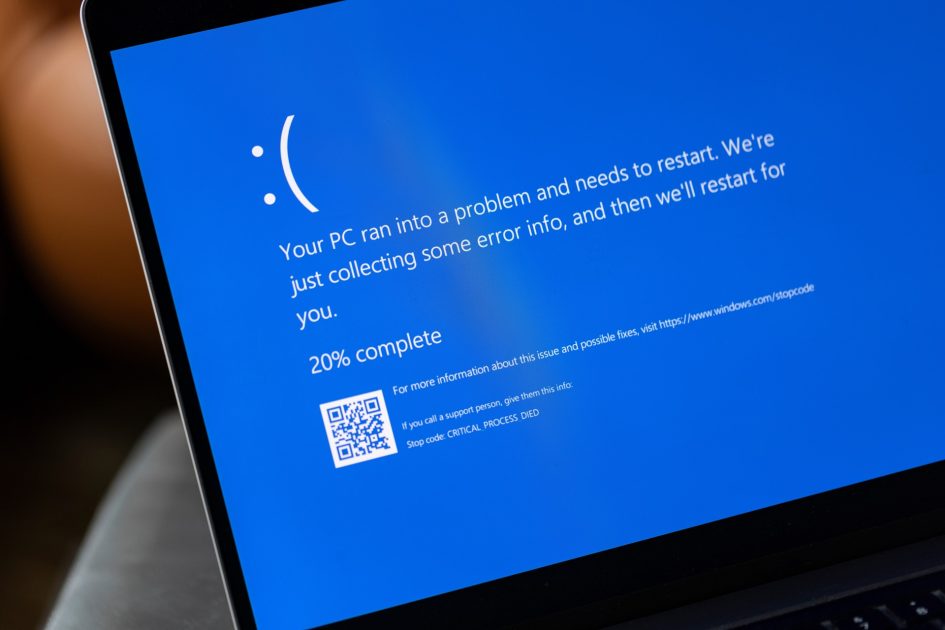
By Align Me | News, Tech Tips | No Comments
We all know how frustrating it is to experience a sudden and unexpected computer shutdown (especially when you forgot to save that file you’ve been working on). But what if you multiplied that frustration by a few million?
That’s what happened last Friday when 8.5 million people around the world experienced the “Blue Screen of Death” simultaneously.
Only this time, no amount of restarts or ctrl alt dlt-ing could bring their PCs back to life.
Cyber security company Crowdstrike has taken the blame for the outage, which grounded planes, halted broadcasts and left shoppers at supermarket check-outs without a way to pay for their groceries.
When one small move can take out thousands of systems and interrupt the lives of millions, it shows us just how fragile our digital lives can be – and how important it is to be prepared for these chaotic and not-so-rare disasters.
Want to review your current Cyber Security and IT setup and discover how you can implement a disaster recovery plan? We can help.
How it all happened
On Friday afternoon (AEST) Crowdstrike, a leading cyber security company, released an update to its “Falcon” sensor for Windows. However, the update proved to be faulty, triggering an error in the configuration file and leading to catastrophic operating system failures.
The resolution wasn’t a simple restart, either. IT technicians everywhere were required to manually intervene to delete faulty files and complete system restorations, a process that took days.
This led to severe disruptions across numerous sectors, including major news organisations, healthcare providers, airlines, and government offices, which were all impacted by:
- System instability and crashes that disrupted critical services and operation
- Significant operational downtime
- Increased risk of exploitation and cyber attacks
- Time-consuming and labour-intensive manual intervention
An opportunity to implement proactive responses
By now, most businesses impacted by the incident are up and running, with all systems back to normal. But that doesn’t mean it didn’t have a major impact on Windows users and their customers.
Microsoft and Crowdstrike are widely trusted and respected providers who service millions. But not even they are immune from cyberattacks or errors. They likely won’t lose too many customers due to the outage, but it’s safe to say they’ll check twice now before issuing an update.
It just goes to show that businesses will never have full control over the systems they rely on to operate, and so will always be somewhat at risk of disruptions. The good news is that while you can’t control it, you can be prepared for it.
Earlier this week, our team came together to discuss the outage, its impact, and how we could support our clients in the aftermath. Whether you’ve been victim to an outage or disruption, now is the right time to review your operations and backup plans.
This includes:
- Discussing risks and the impact of outages. Last week, we saw that major disruptions can happen to anyone at any time—usually when you least expect it. Knowing your risks and how an outage might impact your operations ensures you’re prepared for the worst and makes these events less stressful if they do happen.
- Reviewing your Disaster Recovery (DR)/fallback plan. When a critical outage occurs, what is the plan to keep things going? Is the fallback plan susceptible to the same core problem that caused the outage in the first place? (ie. if there is a Microsoft outage, you don’t want your failover site to also be Microsoft-centric).
- Testing your DR plan to ensure it will work when you need it to. Having implemented a plan to mitigate a critically disruptive outage, the mitigation measures need to be tested BEFORE disaster strikes. Regularly testing ensures everything is in working order (or you can rectify if it’s not).
5 steps you can take right now to avoid potential disaster
These days, cyber outages and attacks are like having your luggage go missing at the airport. If it hasn’t happened to you yet, it’s probably just a matter of time. That’s why we get travel insurance.
These five steps are like insurance for your operations. They won’t prevent interruptions, but they’ll help you get on with your day faster if disaster strikes.
- Review your DR plan (or, seek support in writing one if needed) to determine whether it would stack up if an incident like this occurred in the future.
- Play it out – put yourself in the shoes of a company that was impacted by the incident and play out the steps in your DR plan to assess each possibility.
- Review your security and backup posture – have your IT provider review the measures you currently have in place, referring to your DR plan and identify any gaps in your existing systems
- Invest in necessary upgrades – if your existing systems fail the tests in steps 1, 2 or 3, consider the necessary investments required to bring them up to scratch.
- Repeat – schedule steps 1 through 4 on a regular basis to ensure you remain proactive and prepared.
If you’re unsure how best to test, review or implement a Disaster Recovery plan, we can help. We’ll help you review your current systems and processes and ensure you’re prepared for anything that comes your way.
Contact us today to learn more about how we can help you take your strategy to the next level.
